

A feltáró adatelemzés (EDA) elvégzésekor fontos, hogy ne csak Te (az elemző) készülj fel, hanem az adatok is. Ahogy az előző bejegyzésben már említettük, egy kis előkészület gyakran jelentős időmegtakarítást jelent később. Tehát nézzük át hol tartunk jelenleg, majd folytassuk a feltárási folyamatot az adatok előkészítésével.
A sorozat első részében bemutattuk az általunk használt adatelemzési keretrendszert. Bemutattuk azt a példa adatsort is, amelyet a keretrendszer különböző fázisainak és szakaszainak illusztrálására fogunk használni.
Ezután megismerkedtünk az adatkészlettel, azonosítva az abban kódolt információk és entitások típusait. Áttekintettük azokat az adatátalakítási és vizualizációs módszereket is, amelyeket később az adatok feltárásához és elemzéséhez fogunk használni. Most a keretrendszer előkészítési szakaszának utolsó lépésénél tartunk, a létrehozás szakaszánál, ahol a célunk az lesz, hogy további kategória mezőket hozzunk létre, amelyek megkönnyítik az adatok feltárását és lehetővé teszik azok új perspektívákból való megtekintését.
Az oszlopok átnevezése intuitív nevekre
Mielőtt azonban belevágnánk a kategóriák létrehozásába, lehetőségünk van finomítani a kategorizálási erőfeszítéseinken azáltal, hogy megvizsgáljuk az adatok oszlopait és meggyőződünk arról, hogy a címkéik intuitív módon közvetítik-e azt, amit képviselnek. Csakúgy, mint az előkészítés egyéb lépései esetében, ha most megváltoztatjuk őket, akkor nem kell emlékeznünk arra, hogy mit jelentenek a „displ” vagy a „co2TailpipeGpm” kifejezések, amikor később megjelennek a diagramon. Tapasztalatok szerint ezek a kis, részletekre figyelő fejlesztések a folyamat elején általában összeadódnak és megőrzik azokat a kognitív ciklusokat, amelyeket később felhasználhatunk az insightok kinyerésére.
Az alábbi kód segítségével átnevezhetjük az oszlopokat:

Gondolatok a kategorizálásról
Miután az oszlopneveket intuitívabbá tettük, szánjunk egy kis időt arra, hogy elgondolkodunk a kategorizálás fogalmán, és megvizsgáljuk az adatkészletünkben jelenleg létező kategóriákat. A legegyszerűbb szinten a kategorizálás csupán az emberek információszerkezeti módszere – azaz, ahogyan a komplexitásból hierarchikus rendet teremtünk. A kategóriák az entitások közös tulajdonságai alapján alakulnak ki, és különböző perspektívákat kínálnak, amelyekből rátekinthetünk adatainkra.
Ebben a szakaszban elsődleges célunk olyan további kategóriák létrehozása, amelyek segítenek adataink további szervezésében. Ez nemcsak a feltáró elemzés szempontjából lesz előnyös, hanem a gépi tanulás vagy modellezés szempontjából is, amelyek az adatelemzési folyamat későbbi szakaszaiban kerülhetnek sorra. A tapasztalt adatelemzők tudják, hogy minél jobban szervezik az adataikat, annál jobb downstream elemzéseket tudnak végrehajtani, és annál több informatív jellemzővel tudják ellátni gépi tanulási modelleiket.
A keretrendszer ezen szakaszában három különböző módon hozunk létre további kategóriákat:
- Kategória aggregáció (Category Aggregations)
- Folyamatos változók csoportosítása (Binning Continuous Variables)
- Klaszterezés (Clustering)
Miután tisztában vagyunk azzal, hogy mit és miért csinálunk, kezdjünk neki.
Kategória aggregáció (Category Aggregations)
Az első módszer, amellyel további kategóriákat hozunk létre az, hogy meghatározzuk a lehetőségeket magasabb szintű kategóriák létrehozására a már meglévő változókból az adatkészletünkben. Ehhez meg kell értenünk, hogy jelenleg milyen kategóriák léteznek az adatokban. Ezt úgy tehetjük meg, hogy végigfutunk az oszlopokon és kinyomtatjuk az egyes oszlopok nevét, az egyedi értékek számát és az adattípust.
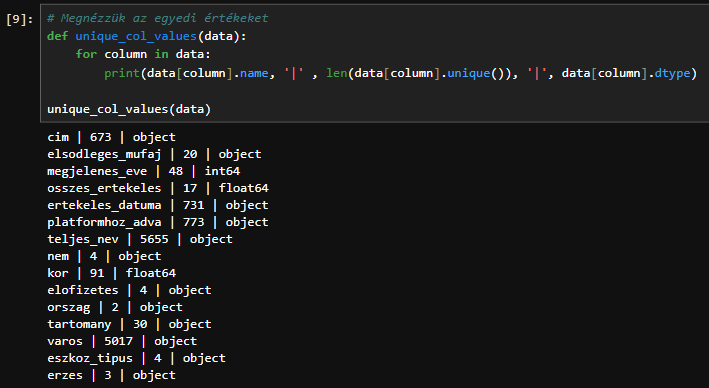
A kimenetet elnézve egyértelmű, hogy vannak numerikus oszlopok (float64) és kategorikus oszlopok (object).
cim | 673 | object
elsodleges_mufaj | 20 | object
megjelenes_eve | 48 | int64
osszes_ertekeles | 17 | float64
ertekeles_datuma | 731 | object
platformhoz_adva | 773 | object
teljes_nev | 5655 | object
nem | 4 | object
kor | 91 | float64
elofizetes | 4 | object
orszag | 2 | object
tartomany | 30 | object
varos | 5017 | object
eszkoz_tipus | 4 | object
erzes | 3 | object
Az adatok összesítésekor és összefoglalásakor túl sok kategória problémát jelenthet. Az átlagos ember rövid távú munkamemóriája egyszerre 7 objektumot képes tárolni. Ennek megfelelően az a tapasztalat, hogy ha egy kategóriában 8–10 diszkrét értéket meghaladunk, egyre nehezebb átfogó képet kapni az egész adathalmaz felosztásáról.
Célunk az, hogy megvizsgáljuk az egyes kategóriaváltozók értékeit és meghatározzuk, hol van lehetőség azok magasabb szintű kategóriákba történő összevonására. Ez általában úgy történik, hogy a jelenlegi kategóriákból származó információkat és a rendelkezésére álló (vagy megszerzhető) domain ismereteket kombináljuk.
Például nézzük meg az „osszes_ertekeles” oszlop aggregálását, amely 17 különálló értéket tartalmaz az adathalmazban. A túl sok kategória miatt nehéz betekintést nyerni, mivel az aggregált metrikák több kategóriára oszlanak, mint amit rövid távú memóriánk képes befogadni. Viszont tudnánk ezt magasabb szinten is kategorizálni.
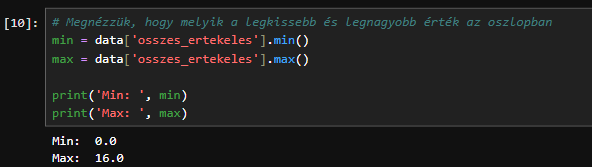
Nézzük meg, hogy melyik a legkissebb és legnagyobb érték az oszlopban:
Létrehozunk egy új oszlopot és négy kategóriára bontjuk az értékeléseket:
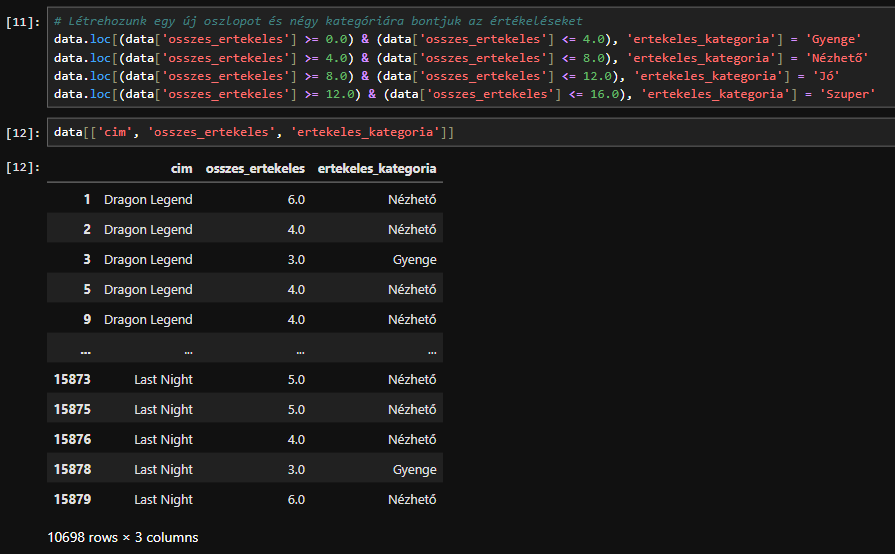
Tehát a 17 egyedi értékelésből csináltunk négy kategóriát: Gyenge, Nézhető, Jó, Szuper
Ezzel a néggyel már sokkal könyebben tudunk számolni.
Fontos megjegyezni, hogy az ebben a szakaszban végzett műveletek során új kategóriákat hoztunk létre, de az eredeti kategóriákat nem írtuk felül. Olyan további mezőket hoztunk létre, amelyek lehetővé teszik számunkra, hogy az adatkészletben szereplő információkat különböző (gyakran magasabb) szinteken tekintsük meg.
Folyamatos változók csoportosítása (Binning Continuous Variables)
Az adatokban további kategóriákat hozhatunk létre úgy is, hogy egyes folyamatos változókat csoportosítunk – azaz küszöbérték vagy eloszlás alapján különböző kategóriákba soroljuk őket. Ezt többféle módon is megtehetjük, de mi a kvintileket fogjuk használni, mert így kapunk egy középső kategóriát, két, attól kissé magasabb és alacsonyabb kategóriát, majd két szélső kategóriát a két végén. Az a tapasztalat, hogy ez egy intuitív módszer a dolgok felosztására és bizonyos konzisztenciát biztosít a kategóriák között.
A binning lényegében megvizsgálja az adatok eloszlását, létrehozza a szükséges számú bin-t az értékek tartományának felosztásával (egyenletesen vagy explicit határok alapján), majd a rekordokat a folyamatos értéküknek megfelelő bin-be sorolja. A Pandas rendelkezik egy qcut() metódussal, amely rendkívül egyszerűvé teszi a binninget, ezért használjuk azt az általunk azonosított folyamatos változók mindegyikéhez kvintilek létrehozására.
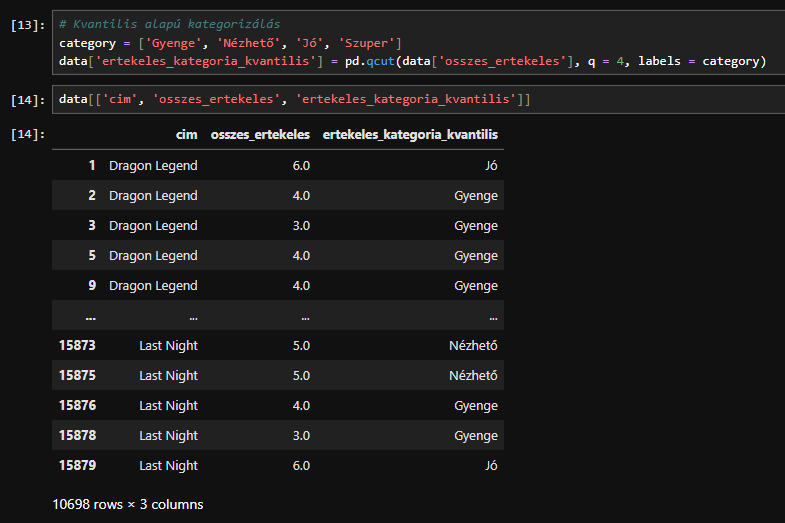
A qcut() automatikusan felosztja az adatokat egyenlő elemszámú csoportokra a megadott szám alapján. Kategóriákat (bin-eket) ad vissza, amiket felhasználhatsz elemzéshez vagy vizualizációhoz.
Klaszterezés (Clustering)
Az adatok előkészítésének utolsó lépése a csoportosítás további kategóriák létrehozása céljából. Számos oka van annak, hogy miért jó a klaszterezést erre a célra használni.
Először is, egyszerre több mezőt is figyelembe vehetsz, míg a többi kategorizálási módszer csak eggyet. Ez lehetővé teszi, hogy olyan entitásokat kategorizáljunk együtt, amelyek több attribútum tekintetében hasonlóak, de az egyes attribútumok tekintetében nem elég hasonlóak ahhoz, hogy egy csoportba sorolhatók legyenek.
A klaszterezés automatikusan új kategóriákat hoz létre, ami sokkal kevesebb időt vesz igénybe, mint ha magunknak kellene átnézni az adatokat és azonosítani kellene azokat a mintákat, amelyek alapján kategóriákat hozhatunk létre. A rendszer automatikusan csoportosítja az egymáshoz hasonló elemeket.
A harmadik ok amiért jó a klaszterezést az, hogy néha olyan módon csoportosítja az elemeket amire Te mint ember, talán nem is gondoltál volna. Ez példa arra, hogy a gépek milyen értéket tudnak adni ami hasznos lehet az emberek számára.
Az első lépés az, hogy kiválasztjuk a klaszterezéshez használni kívánt oszlopot vagy oszlopokat. Ezek numerikus értékeket tartalmazó oszlopok lesznek, mivel a klaszterezési algoritmusnak távolságokat kell kiszámítania ahhoz, hogy a hasonló járműveket egy csoportba sorolja.

Ezután méretezni szeretnénk azokat a jellemzőket, amelyeket klaszterezni fogunk. A változók normalizálására és skálázására számos módszer létezik, de most viszonylag egyszerűen fogjuk kezelni a dolgokat és csak a scikit-learn „MaxAbsScaler” funkcióját fogjuk használni, amely minden értéket eloszt az adott jellemző maximális abszolút értékével. Ez megőrzi az adatok eloszlását, és minden mező értékeit 0 és 1 közötti számmá alakítja (technikailag -1 és 1 közötti számmá, de negatív értékek nincsenek).
Elöszőr telepítsük a scikit-learn gépi tanulás modult, ha még nem tettük meg.
pip install scikit-learn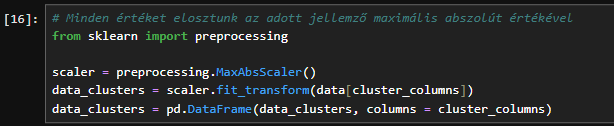
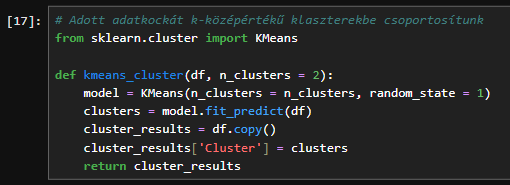
Most, hogy a funkcióink méretezésre kerültek, írjunk néhány függvényt. Az első függvény a „kmeans_cluster”, amely egy adott adatkockát k-középértékű klaszterekbe csoportosít, ezután visszaadja az eredeti adatkockának egy másolatát, amelyhez ezek az értékek egy Cluster nevű oszlopban lesznek hozzáfűzve.
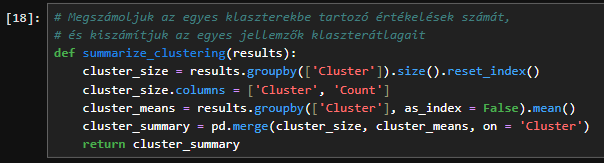
A második függvényünk, a „summarize_clustering” megszámolja az egyes klaszterekbe tartozó járművek számát, és kiszámítja az egyes jellemzők klaszterátlagait. Az összesítést és az átlagokat egyetlen adatkockába egyesíti, majd visszaküldi nekünk az összefoglalót.
Most már rendelkezünk a szükséges funkciókkal, így a következő lépés az adatok tényleges csoportosítása. De várjunk csak, a „kmeans_cluster” funkciónknak elvileg több klasztert kell elfogadnia. Hogyan határozzuk meg, hogy hány klasztert szeretnénk?
Számos módszer létezik ennek kiszámítására, de az egyszerűség kedvéért most csak beírunk néhány számot, és vizualizáljuk az eredményeket, hogy egy jó becsléshez jussunk. Emlékszel arra, hogy a bejegyzés elején megpróbáltuk a kategorikus változókat 8–10 diszkrét értékre összesíteni? Itt is ugyanazt a logikát fogjuk alkalmazni. Kezdjük 8 klaszterrel, és nézzük meg, milyen eredményeket kapunk.

A fenti kód futtatása után a „cluster_summary” kódja a következőhöz hasonlóan fog kinézni.
| Cluster | Count | osszes_ertekeles |
| 0 | 1174 | 0.521987 |
| 1 | 1992 | 0.250000 |
| 2 | 1838 | 0.375000 |
| 3 | 1244 | 0.187500 |
| 4 | 2223 | 0.312500 |
| 5 | 364 | 0.667754 |
| 6 | 1283 | 0.437500 |
| 7 | 580 | 0.115948 |
A Count oszlopot megnézve látható, hogy vannak olyan klaszterek, amelyek jelentősen több rekordot tartalmaznak (pl. a 4. klaszter), és vannak olyanok, amelyek jelentősen kevesebbet (pl. a 5. klaszter). Ezen kívül azonban nehéz bármi informatívat észrevenni az összefoglalásban. Nem tudom Te hogy vagy vele, de számomra az összefoglaló többi része csak egy csomó tizedesjegynek tűnik egy táblázatban.
Ez egy kiváló alkalom arra, hogy vizualizációval gyorsabban nyerjünk betekintést az adatokba. Csak néhány import utasítással és egy sor kóddal megvilágíthatjuk ezt az összefoglalót egy hőtérképen, hogy lássuk a kontrasztot a tizedesjegyek és a különböző klaszterek között.
Elöszőr telepítsük a matplotlib és seaborn modulokat, ha még nem tettük meg.
pip install matplotlib seaborn
Ezen a hőtérképen a sorok a jellemzőket, az oszlopok pedig a klasztereket jelölik így összehasonlíthatjuk, hogy az oszlopok mennyire hasonlítanak vagy különböznek egymástól. A jellemzők klaszterezésének célja, hogy a klaszterekből értelmes kategóriákat hozzunk létre, ezért olyan pontra szeretnénk eljutni, ahol egyértelműen meg tudjuk különböztetni őket egymástól. Ez a hőtérkép lehetővé teszi, hogy ezt gyorsan és vizuálisan megtegyük.
Ezt a célt szem előtt tartva nyilvánvaló, hogy valószínűleg túl sok klaszterünk van, mert:
- Az 1. és 4. klaszter nagyon hasonló.
- A 2. és 6. klaszter is hasonló.
A hőtérkép jelenlegi állapotát elnézve úgy néz ki, hogy a klaszterek számát felére csökkenthetjük és így tisztább határokat kapunk. Futtassuk újra a klaszterezés 4 klaszterre és nézzük meg milyen eredményeket kapunk.
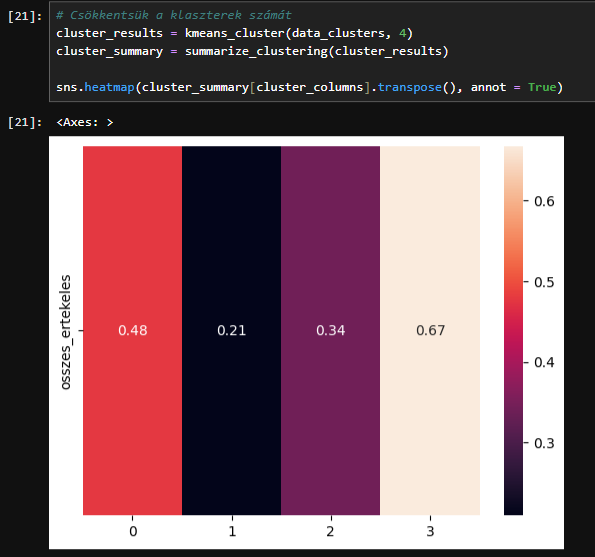
Ezek a klaszterek jobban elkülönülnek egymástól.
Most már van néhány jó klaszterünk, de még mindig van egy problémánk. Nehéz megjegyezni, hogy a 0, 1, 2 és 3 klaszterek mit jelentenek, ezért a következő lépésként szeretnék értelmes neveket adni a klasztereknek a tulajdonságaik alapján. Ehhez meg kell néznünk az egyes klaszterek jellemzőjének szintjét és intuitív, természetes nyelvű leírásokat kell kitalálnunk számukra. Itt kreatívak lehetünk de ne feledjük, hogy a cél az, hogy emlékezzünk a klaszterekhez rendelt címkék jellemzőire.
- A 3. csoportba tartozó értékelések „Szuper” kategóriát kapnak.
- A 0. csoportba tartozó értékelések „Jó” kategóriát kapnak.
- A 2. csoportba tartozó értékelések „Nézhető” kategóriát kapnak.
- A 1. csoportba tartozó értékelések „Gyenge” kategóriát kapnak.
Miután megalkottuk ezeket a leíró neveket a klasztereinkhez, adjunk hozzá egy „ertekeles_kategoria_cluster” oszlopot a „cluster_results” adatkerethez, majd másoljuk át a klaszter neveket az eredeti adatkeretbe.
Következtetés
Ebben a bejegyzésben többféle módszert vizsgáltunk az adatkészlet előkészítésére a feltáró elemzéshez.
Először megnéztük a rendelkezésünkre álló kategorikus változókat és megpróbáltuk megtalálni a lehetőségeket azok magasabb szintű kategóriákba történő összevonására.
Ezután néhány folytonos változónkat kategorikus változókká alakítottuk át úgy, hogy azok értékeinek relatív magas vagy alacsony szintje alapján negyedes skálára osztottuk őket.
Végül klaszterezést alkalmaztunk, hogy hatékonyan hozzunk létre olyan kategóriákat, amelyek automatikusan több mezőt is figyelembe vesznek.
Mindezen előkészületek eredményeként most már több oszlopunk is van, amelyek értelmes kategóriákat tartalmaznak és különböző perspektívákat nyújtanak adatainkról és lehetővé teszik, hogy minél több betekintést nyerjünk.
Most, hogy megvannak ezek a kategóriák, adatkészletünk nagyon jó állapotban van ami azt jelenti, hogy továbbléphetünk adatfeltárási keretrendszerünk következő szakaszába. A következő bejegyzésben az Explore Phase első két szakaszát fogjuk megnézni, és különböző módszereket mutatok be az adatok vizuális összesítésére, forgatására és a mezők közötti kapcsolatok azonosítására.
A post-sorozat többi tagja